对于真假百度蜘蛛,相信SEO及站长们已经有明确的手段去辨别了。百度也在官方通告了如何去判别伪装成百度蜘蛛的抓取,详情请参考这篇文章:http://www.baidu.com/search/spider.htm
假蜘蛛对我们网站的危害是巨大的,具体有:
占用网站带宽,导致网站流量上升,增加额外开销,在有限带宽的前提下,阻碍了正常蜘蛛的抓取,误导了我们在对网站开展SEO工作时的思路,部分伪装成假蜘蛛的采集工具剽窃了我们的工作,我们看到,网上有很多人在分享如何“捉住”假蜘蛛的文章,但这些文章只是千篇一律的描述了“捉住”假蜘蛛的过程及操作方法。却没有分享从如何真正的判别蜘蛛的真伪。
作者本人最近在对一个电商网站进行SEO优化时,就碰到了这样一个案例,险些导致将真蜘蛛错当假蜘蛛来处理。
一、发现“假蜘蛛”
SEO优化要依靠大量的分析和数据来实现,其中日志分析是重中之重,在日志中我们可以看到很多平时统计工具无法看到的数据和事实。
每周三我都要对该电子商务网站进行周日志的分析,以便来统计上一周的优化效果,在本周进行对网站日志进行分析查看时,我发现了几个不属于认识中的“蜘蛛IP”,如图:

我们知道,百度蜘蛛一般来自于202.181.108.* 和123.125.71.* 这两个IP段(顺便科普一下,这两个IP段的百度蜘蛛没有所谓高权重和降权之分)。显然这三个IP在“常识”中,不属于百度蜘蛛所属的IP段。为了确保不误杀百度蜘蛛,笔者用nslookup ip命令反解了此IP,得到以下信息:
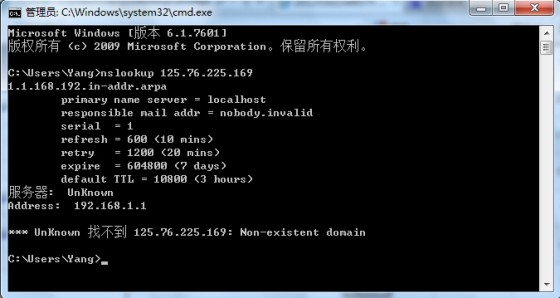
这个时候,基本已经可以确定该IP不属于百度蜘蛛的IP段,是一个“假蜘蛛”,我们需要屏蔽该IP释放那些被占用的带宽。
二,误会“假蜘蛛”
就在要对以上提到的三个IP进行屏蔽的时候,笔者突然想到,这个电商网站在上周通知我他们要使用安全宝服务,需要将DNS解析到安全宝的服务器上,而安全宝则会根据用户的访问情况,选择距离最近的一个节点进行CDN加速。
在我之前的例行SEO检查中,发现网站IP被解析到了陕西的一个IP上,而这个网站IP和这次我从网站日志中发现的三个“假蜘蛛”IP属于同一IP段。为了验证这个推测,我又重新仔细查看了网站日志,发现谷歌蜘蛛和搜狗蜘蛛也来自于之前三个IP(之前对网站日志进行了拆分,只查看百度的情况,因为网站是针对百度做SEO的)。
这下子总算清楚了,这些所属IP的蜘蛛不是假蜘蛛,而是货真价实的百度蜘蛛、谷歌蜘蛛和其他搜索引擎的蜘蛛。只不过因为他们通过了一次CDN节点,所以造成了他们的来源IP是一致的。
三,虚拟主机如何产生“假蜘蛛”
由此笔者突然想到,之前在阅读相关文章的时候,经常会看到有站长抱怨发现假蜘蛛,来自XX机房(就那么一两家机房)。
这是一件很奇怪的事情,莫非采集工具和假蜘蛛都产自这个机房?事实自然不是那样的,而是:
很大一部分发现假蜘蛛的站长,所使用的是某主机供应商提供的集群主机,或类似性质的虚拟主机集群性质的虚拟主机,同CDN的道理是相同的,即将客户的空间和站点资料同步到同一个群组的所有服务器上蜘蛛的来源不同,一些是直接访问站点的,另一些是通过一些外链访问站点的。而这些通过外链访问站点的蜘蛛,会就近通过CDN节点访问CDN节点每家公司都不一样,但大致分为地域大区(不是省)和电信、网通这样的方式划分那些通过CDN节点访问网站的蜘蛛,来源IP自然不是从北京总部出发时的IP
最终事情得到了很好的解决,该电商网站自优化以来效果一直良好,虽然采用了CDN,但事实证明CDN对搜索引擎而言没有任何障碍,反而有利于网站速度和提高用户体验。
这个SEO案例也同时告诉我们,网上的SEO教程是会过时的,随着互联网的进步,我们SEO也要学会理智的去对待一些教程和分享,要有质疑和勇于实践的精神,同时对互联网的一些基本的技术知识要有所了解。
本文由兰州SEO-东方惠梵优化团队杨帆AimarYang原创,转载请保留链接:http://www.easthv.cc/blog/lanzhouseo/fake-baiduspider-cdn/


 粤公网安备 44010402000282号
粤公网安备 44010402000282号